Qzone
Qzone
 微博
微博
 微信
微信

日前,由搜狗创始人王小川创立的百川智能方面宣布,推出、并开源拥有70亿参数量的中英文预训练大模型“baichuan-7B”。据悉,目前baichuan-7B大模型已在Hugging Face、Github 以及Model Scope平台发布。
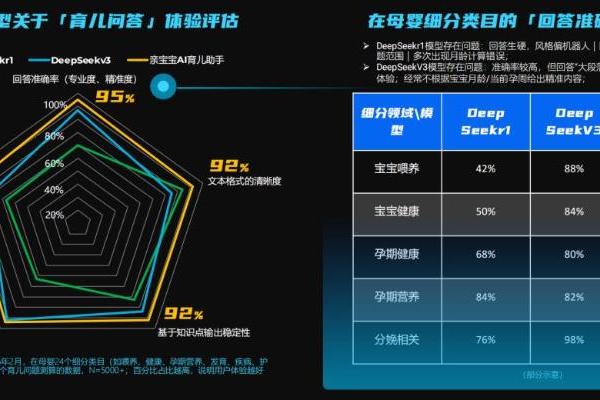
据了解,为验证该模型的各项能力,baichuan-7B在C-Eval、AGIEval和Gaokao三个最具影响力的中文评估基准进行了综合评估,并且均取得了优异的成绩,已成为同等参数规模下中文表现最优秀的原生预训练模型。其在中文C-EVAL的评测中,baichuan-7B的综合评分达到了42.8分,在AGIEval评测里的综合评分达到34.4分,在GAOKAO评测中的综合评分则为36.2分。
此外,baichuan-7B不仅中文方面表现优异,在英文上表现同样亮眼。例如在MMLU的评测中,baichuan-7B的综合评分达42.5分,大幅领先英文开源预训练模型LLaMA-7B的34.2分,以及中文开源模型ChatGLM-6B的36.9分。
据悉,由于秉持开源精神,baichuan-7B的代码采用了Apache-2.0协议,模型权重为免费商用协议,因此只需进行简单登记即可免费商用。而baichuan-7B此次开源的内容,则包含推理代码、INT4量化实现、微调代码,以及预训练模型的权重。其中,微调代码方便用户对模型进行调整和优化,推理代码与INT4量化实现则有助于开发者低成本地进行模型的部署和应用,预训练模型权重开源后,用户可直接使用预训练模型进行各种实验研究。
目前,北京大学和清华大学已率先使用baichuan-7B模型推进相关研究工作,并计划未来与百川智能进入深入合作,共同推动baichuan-7B模型的应用和发展。
对此,清华大学互联网司法研究院院长、计算机系教授刘奕群表示,baichuan-7B模型在中文上的效果表现十分出色,其免费商用的开源方式也展现出了开放的态度,不仅贡献社区、还能推动技术发展。据其透露,该团队计划正基于baichuan-7B模型开展司法人工智能领域的相关研究。
北京大学人工智能研究院助理教授杨耀东认为,baichuan-7B模型的开源将对于中文基础语言模型的生态建设,以及学术研究产生重要推动作用。同时他表示,将持续关注相关领域探索,并且在中文大语言模型的安全和对齐上进行进一步深入研究。
百川智能CEO王小川则表示,“此次开源模型的发布是百川智能成立2个月后的第一个里程碑,对百川智能而言是一个良好的开局。baichuan-7B模型不仅能为中国的AGI事业添砖加瓦,也将为世界大模型开源社区贡献新的力量。”
【以上内容转自“三易生活网”,不代表本网站观点。如需转载请取得三易生活网许可,如有侵权请联系删除。】
延伸阅读:







安兔兔2025-03-28 18:1803-28 18:18






 点击下方菜单栏 “
点击下方菜单栏 “  ” 选择 “分享”, 把好文章分享出去!
” 选择 “分享”, 把好文章分享出去!

 为推荐给更多人
分享写下你的想法>
为推荐给更多人
分享写下你的想法>